








スポンサーリンク
区切り文字の前と後とに分ける
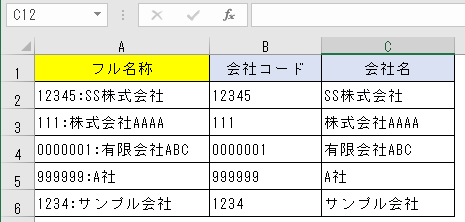
上図のA列では、会社のコード・名称が「:」記号で接続されている。
これをB列・C列のように、コードと名称に分ける、すなわち「:」記号の前と後とに分けたいというのは、定番の問題だ。
正解―FIND関数などの組み合わせ―
ではB2セル・C2セルに入れる計算式について正解を書くと、下記のようになる。
B2セルに入れる式( 「:」記号より前の文字を抽出する )
=LEFT($A2, FIND(“:”,$A2) – 1)
C2セルに入れる式( 「:」記号より後の文字を抽出する )
=RIGHT($A2, LEN($A2) – FIND(“:”,$A2) )
2つも3つも関数を組み合わせた複雑な計算式になってしまうが、どうもこれ位しか無い。
こういう、区切り文字の前・後に分けるシンプルな専用関数があれば良いのだが。
今回は、上記の正解で使っているFIND関数と、類似のSEARCH関数について取り上げる。
その他に使用されている、LEFT・RIGHT・LENといった関数については、以前の記事に書いている。

FIND関数・SEARCH関数の用途
今回取り上げるFIND関数・SEARCH関数は、単体で使用することは、ほとんど無いだろう。
というより、今回の例題そのまま、何かの区切り文字に対する前後の文字を抽出するという目的でしか使わないという人も多いと思う。
だからまず、今回の例題において、複雑な計算式の中でどのような意味合いで用いられているのかさえ押さえておけば、ひとまずはOKだ。
それ以外の用途に対する応用利用などというのは、その後で余裕があれば試みるという程度で良いだろう。
FIND関数・SEARCH関数の共通点
引数の構成
FIND関数・SEARCH関数は類似のものだが、引数の構成はどちらも同じで、
SEARCH( 検索文字列 , 対象 , [開始位置] )
というようになっている。
「Excel」という文字列を、A1セルに入っている文字の中から検索したいという例では、
=FIND(“Excel” , A1)
=SEARCH(“Excel” , A1)
といった書き方になる。
この例では引数の[開始位置] というやつは使っていないが、大抵の場合は指定せずに使えば良いので、今回の記事でも省略する方法をメインで紹介する。一応[開始位置]の使い方についても、後で取り上げるけど。
半角文字列での検索
FIND関数とSEARCH関数は、LEN・LEFT・RIGHT・MID関数といった他の文字列関数と同様、末尾に「B」を付けると半角文字列での検索になる。
その使い分けが必要な場面もあるだろう。
関数の末尾に「B」を付けた場合は、半角バイト数で文字数をカウントする。
末尾に「B」を付けなかった場合は、半角全角など関係なく単なる文字数をカウントする。
FIND関数とSEARCH関数の違い
FIND関数とSEARCH関数って何が違うのかは、意識しなくて良い場面ばかりなので、正直言って私も覚えていなくて適当にFIND関数ばかり使っている。
ただ、それら区別が必要なケースもそれなりにはあるだろうし、ひとまず下記に違いを書いておく。
- FIND関数は、大文字と小文字を区別する。ワイルドカードは使えない。
- SEARCH関数は、大文字と小文字を区別しない。ワイルドカードが使える。
というようになっている。
ただ、ひとまず大文字・小文字の区別の仕様だけ覚えておけば良いだろう。ワイルドカードは割とどうでも良いと思う。
| 関数 | 大文字と小文字の区別 | ワイルドカード |
| FIND関数 | 区別する | 使えない |
| SEARCH関数 | 区別しない | 使える |
大文字・小文字の区別
たとえばA2セルに「Microsoft Excel」とある中から、小文字で書いて「excel」の文字列を探したいという場合、FIND関数とSEARCH関数の結果は下図のようになる。

FIND関数では大文字・小文字を区別するので、それを正しく書けていない「excel」の文字で検索するのはエラーになる。
そしてSEARCH関数は大文字・小文字を区別せずどちらでも良いので、結果は11(文字目)であると正しく返される。
ワイルドカード
ワイルドカードといえば、
「*」→何らかの任意文字数の文字列
「?」→何らかの1文字の文字列
だ。下図のように、FIND関数では使えず、SEARCH関数でなら使える。

ただ、FIND関数・SEARCH関数で、わざわざワイルドカードを使用すべき場面があるのか、どうも分からない。
これはほぼ意識しなくて良いだろう。
引数[開始位置]
FIND関数・SEARCH関数は、最後の引数[開始位置] は省略して良いが、指定するとすれば、検索対象文字列が複数ヒットしそれを区別したい場合になるかと思う。そういう場面があまり思いつかないが。
下図では、元の文字列「abc-abc-abc」に対して文字列「b」は3回ずつヒットするわけだが、それをFIND関数・SEARCH関数で引数[開始位置] を指定した結果が次のようになる。
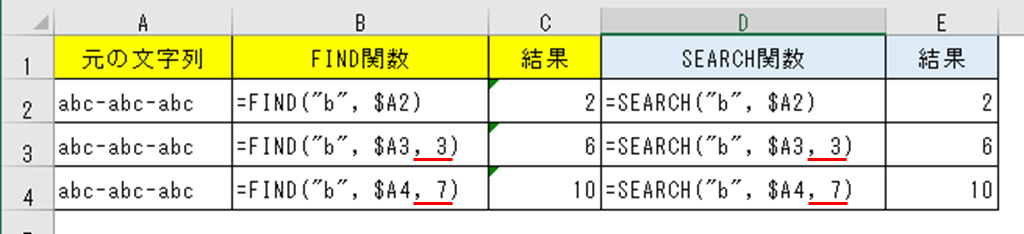
3文字目を起点にすれば、「b」文字は先頭から6文字目に見付かる
7文字目を起点にすれば、「b」文字は先頭から10文字目に見付かる
という結果になる。
あくまで、先頭から何文字目なのかを返すわけなので、用途は限られてくるだろう。
下図のように検索文字「j」が10文字目に一度しかヒットしない場合、引数[開始位置] を指定してもしなくても結果は同じになる。
多くの場合は検索文字が1回しかヒットしないケースを想定すれば良いはずなので、この引数[開始位置]の指定が必要な場面は少ないだろう。

スポンサーリンク