









スポンサーリンク
今回の例題
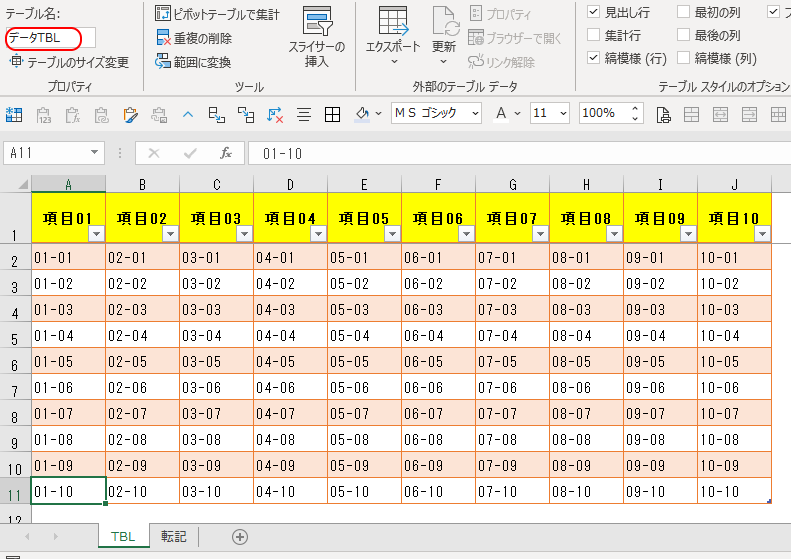
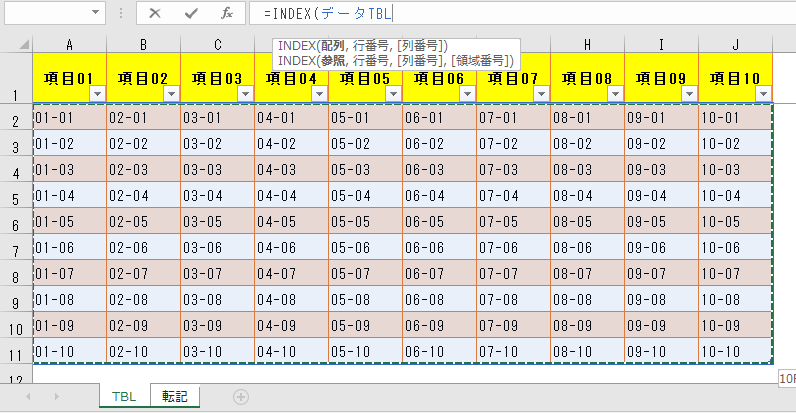
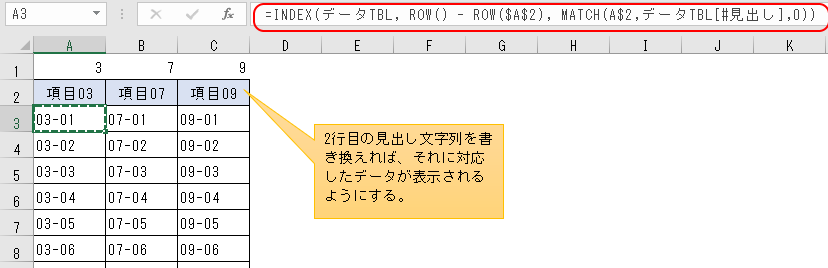
下図はExcelの「テーブル」で、「データTBL」と名前を付けてある。
実際には1行目の見出しには、こんな規則的な名前は付いていなくて、列数も10個どころじゃなく何十個もあるものとする。
では今回やりたいこと。
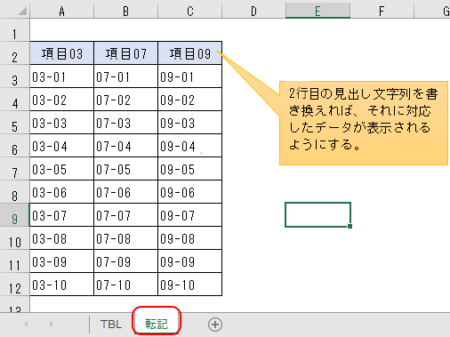
このテーブルに多数ある列の中から好きなものだけ選んで、「転記」シートの2行目にその列見出しの名前を書く。
→そうすると、列見出しの名前に従って3行目以降に、テーブルの対応データがそのまま引っ張ってこられるようにしたい。
なぜ見出しが2行目にあるかって、1行目は作業セルとして使いたいからだけど。
多数ある列の中から好きな列だけ選ぶということ自体は、ピボットテーブルとかPowerQueryでもできるが、今回はそういうのは無し。
あくまで、2行目の列見出しを書き換えればデータも変わるというのを、簡単に実現したいということで進める。
そして、「テーブル」の特性を有効活用した方法でやってみる。
今回の、答え入りサンプルファイルはこちらに保存してある。


作業セルに計算式(MATCH関数)を入れる
今回の「転記」シートの1行目は、作業用の計算式を入れる用途を想定したものだ。
そこには、2行目に書かれたタイトル文字を元に、その項目(列)がテーブル「データTBL」の何列目にあるのかを求める計算式を入れる。
そういう、検索した文字列が何個目のセルかというのを求めるのはMATCH関数だ。
INDEX関数(後述)と組み合わせる使い方が多い関数だけど、必ず使えるようになろう。まあSUMIFSとか他の重要関数を覚えてから後で良いけど。
MATCH関数
MATCH関数の構成は
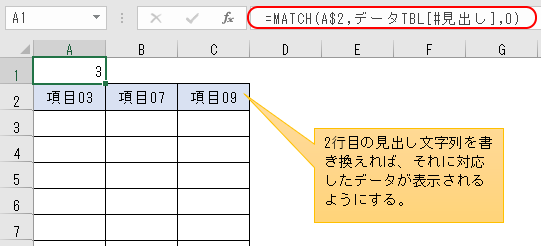
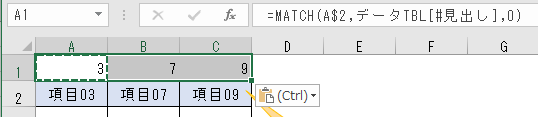
というもので、今回はまずA1セルに
と入れる。
以下、その計算式の説明。
今回入力したMATCH関数の中身
(1)検査値 A$2
列の位置はスライドさせていくが、行が2行目なのは固定にするので、相対参照の$マークの位置は間違わないこと。
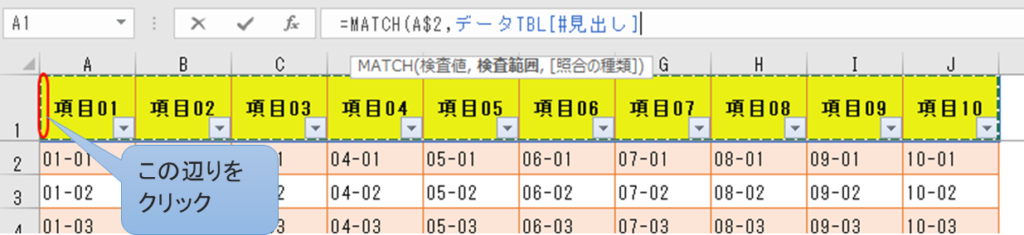
(2)検査範囲 データTBL[#見出し]
MATCH式の入力過程で、テーブル「データTBL」のタイトル行全体をクリック選択すれば、自動でこの文字列が入力される。
そのクリックする位置が、どうも馴染めない人には難しいみたいだけど。
(3)照合の種類 0
今回だけでなくMATCH関数を使う時の多くは、この照合の種類には0(完全一致)を入れる。
そして、A1セルに入れたMATCH関数
=MATCH( A$2 , データTBL[#見出し] , 0)
を、横方向にコピーしよう。
INDEX関数を入れていく
INDEX関数
では次に、3行目以降のデータ部分に入れていく計算式。
先ほどMATCH関数で、何列目のデータを取るか求めたので、次は何行目のデータを取るか求める。
そういう、セルの行数と列数から値を求めるのはINDEX関数だ。
INDEX関数の構成は
で、今回は
と入れてみる。後でもっと別の例も示すけどね。
以下、その計算式の説明。
今回入力したINDEX関数の中身
(1)対象セル範囲 データTBL
元のテーブル「データTBL」の全体(タイトル行は除く)を丸ごと指定する。
INDEX式の入力過程で、テーブル「データTBL」の始点A2セルをクリックしてから、ショートカットキー< Ctrl + Shift + End >で最終セルまで選ぶという方法が、ベストかと思う。
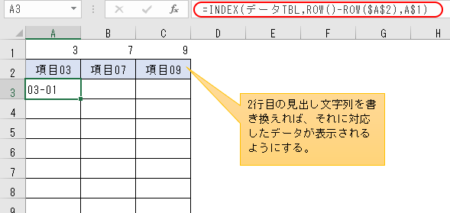
(2)行番号 ROW() – ROW($A$2)
3行目から始まる、「転記」シートのデータ部の各行の行数をROW関数で取得する。
その行数から、タイトル行であるA2セルの行数もROW関数で取得し、それらの差を取ることでデータが何行目か求めていく。
(3)行番号 A$1
先ほど作業用として1行目にセットしたMATCH関数の結果を、ここで利用するということ。
ということで、計算式
=INDEX( データTBL , ROW() – ROW($A$2) , A$1 )
をA3セルにセットした。
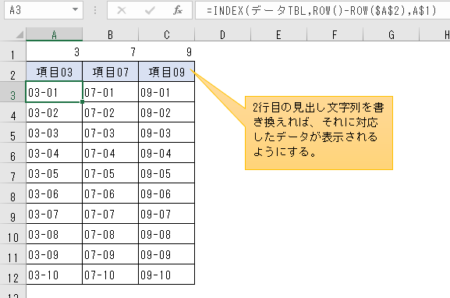
この計算式をコピーして、3行目以降の各セルに貼り付ければ、一応今回の目的は達成できる。
すなわち、2行目の見出し文字列を書き換えれば、それに対応したテーブル「データTBL」の内容を引っ張ってくるように設定できたということだ。
作業用セルを使わない場合
1行目を作業用セルに使わずに、A3セルに直接
=INDEX(データTBL , ROW() – ROW($A$2) , MATCH(A$2,データTBL[#見出し],0) )
と式を入れても、良いことは良い。
ただこの場合、式がやたら長くなるし、この式をコピペしたセル全てでMATCH関数による検索処理が掛かって重くなるイメージがあって、私はあまりやりたくない。
後でまとめて修正が必要になったときも面倒だし。
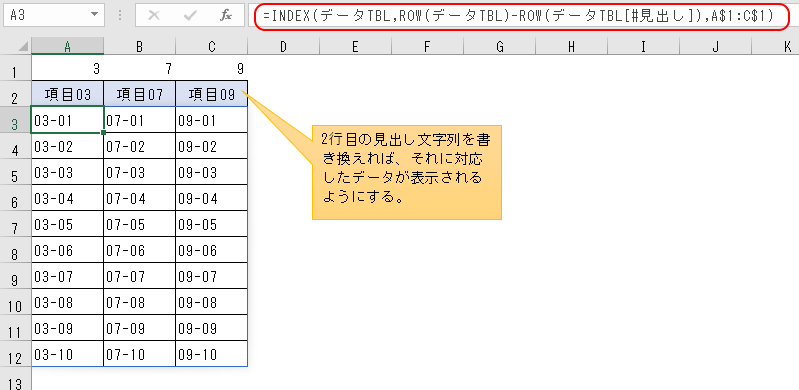
スピルも活用する
スピルを使った正答例
いま設定した数式は、テーブルのデータが1000行あったなら数式も1000行に貼付けていく必要があり、面倒といえば面倒だ。
その手間を更に省くためには、以前も扱った「スピル」が有効だ。
ひとまず、分かりやすく説明を書くのはかなり困難なので、先に答えから書くと、「転記」シートのA3セルに
と書けば、自動的にスピルが作用しデータが埋められてくれる。
ついでに、A1セルに入れた数式は
=MATCH( A$2 , データTBL[#見出し] , 0)
から、
=MATCH(A$2:C$2 , データTBL[#見出し] , 0)
と変更すれば、C1セルまで数式が伸びてくれる。
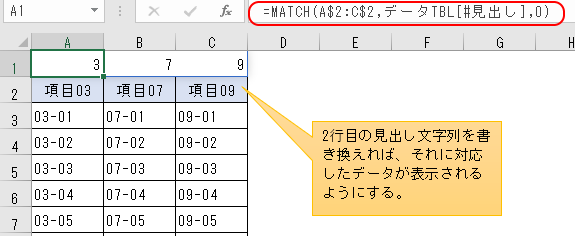
以下、このスピルを使った数式の説明を書いていくけど、テーブルの構造化参照式が絡むことで、どうも分かりやすい説明が難しい。
スピル数式の説明
INDEX関数の構成を再度書くと
だが、スピルにおいてはこの「行番号」「列番号」を、テーブルの行数・列数に合わせて引き伸ばすことになる。
列番号の方は転記シートの1行目で計算したものから取れば良いので簡単だが、問題は行番号の方だ。
この行番号は、「データTBL」の行数分だけ引き伸ばすわけだが、その行数は
ROW(データTBL)
として取得すれば良い。
ただそれでは、「データTBL」のデータ部がシートの何行目から始まるかによって結果が変わってしまうので、テーブルのタイトル行の行数を引くことで、固定値の行数を求める(分かりやすく書きにくい・・・)。
スポンサーリンク