










スポンサーリンク
前回は、ExcelのMicrosoft365バージョンで2022/08に新規追加された関数のうち、配列に関するものを紹介した。
今回はそれに続き、文字列操作に関する関数を扱う。こちらの方が、これまでの文字列操作関数(LEFT、RIGHT、MID、FIND、SEARCHなど)に足りなかったものを埋めてくれており、利用場面が多いのではないだろうか。
今回は、関数の引数については意外に複雑なので、公式サイトの説明をコピペした。実際のところ、任意で入れれば良い引数については、省略すれば良いケースが多いと思うが。


TEXTSPLIT関数
指定した文字列を、区切り記号の出現ごとに、横(縦もある)方向に分割したスピルを実施する。
| text | 分割するテキスト。必ず指定します。 |
| col_delimiter | 列間でテキストをスピルするポイントを示すテキスト。 |
| row_delimiter | テキストを下の行に書き込むポイントを示すテキスト。省略可能です。 |
| ignore_empty | FALSE を指定して、2 つの区切り記号が連続している場合に空のセルを作成します。 既定値は TRUE で、空のセルが作成されます。省略可能です。 |
| match_mode | テキストで区切り記号の一致を検索します。 既定では、大文字と小文字を区別する一致が行われます。省略可能です。 |
| pad_with | 結果を埋め込む値。既定値は #N/A です。 |
下図は、氏名を空白記号で横に区切り、「:」記号が出てきたら縦に行を改めているもの。余りのセルには「End」と埋め込んでいる。

TEXTBEFORE関数
指定した文字列に対し、区切り記号の前の文字を返す。
| text | 検索対象のテキスト。 ワイルドカード文字は使用できません。 必ず指定します。 |
| delimiter | 抽出した後のポイントをマークするテキスト。 必ず指定します。 |
| instance_num | テキストを抽出する区切り記号のインスタンス。 既定では、instance_num = 1 です。 負の数を指定すると、テキストの末尾から検索が開始します。 省略可能です。 |
| match_mode |
テキスト検索で大文字と小文字を区別するかどうかを指定します。 既定では大文字と小文字が区別されます。 省略可能です。 次のいずれかを入力します。 0:大文字と小文字を区別します。 |
| match_end |
テキストの末尾を区切り記号として扱います。 既定では、テキストは完全一致です。 省略可能です。 次のいずれかを入力します。 0:区切り記号をテキストの末尾に一致させないでください。 |
| if_not_found | 一致するものが見つからない場合に返される値。 既定では、#N/A が返されます。 省略可能です。 |
下図は、空白文字の前にある名字を抜き出したもの。
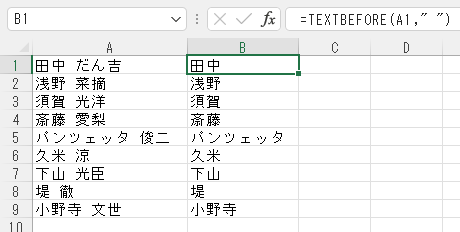
従来の関数でやるなら、
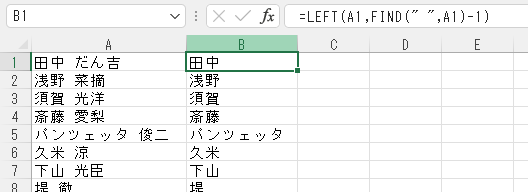
=LEFT(A1,FIND(” “,A1)-1)
といった感じになる。
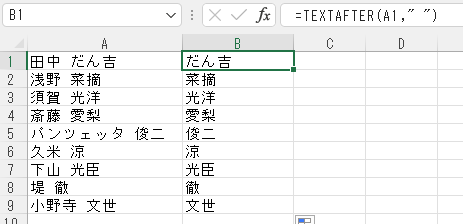
TEXTAFTER関数
指定した文字列に対し、区切り記号の後の文字を返す。
引数についてはTEXTBEFORE関数と同じなので、後は省略。
下図は、空白文字の後にある名前を抜き出したもの。
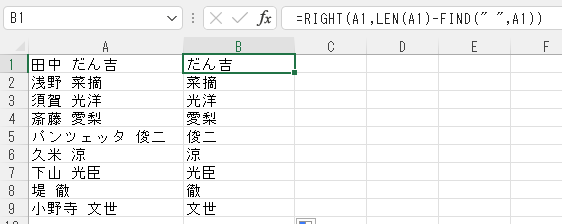
従来の関数でやるなら、
=RIGHT(A1,LEN(A1)-FIND(” “,A1))
といった感じになる。これがとても難しい。
スポンサーリンク




















