








スポンサーリンク
はじめに
以前の記事で、ExcelのPowerQueryでインデックス(行番号)を振る方法を扱った。
また別の記事で、項目 (下図の例でいう「第1カテゴリ」項目) が変わるごとに1増えるインデックス番号を振る方法を扱った。

今回は、これと別のインデックスの振り方をしてみる。
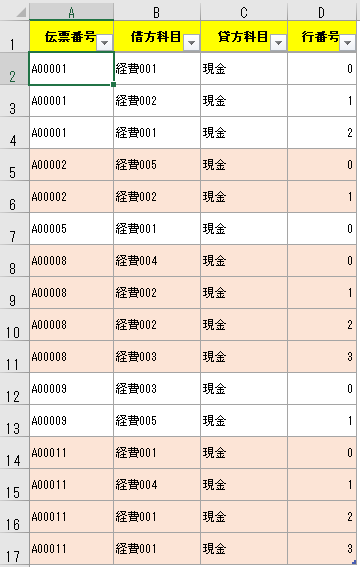
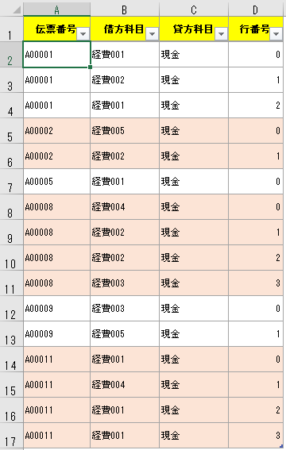
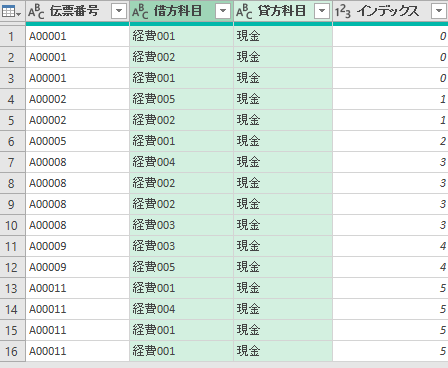
下図の例では「伝票番号」に対して、インデックスである「行番号」を振っている。
そして伝票番号が変わるごとに「行番号」は0開始に戻り、伝票番号が変わらない間は「行番号」は1ずつ増える。
こういうインデックスの振り方をするには、ちょっと難しい方法が必要になる。
インデックス設定(伝票番号が同じ間は同じ番号)
まず、おさらいの意味もあるが、今回やりたい処理の手掛かりの意味も込め、以前にやったように「伝票番号」が変わるごとに1増えるインデックスを振る。
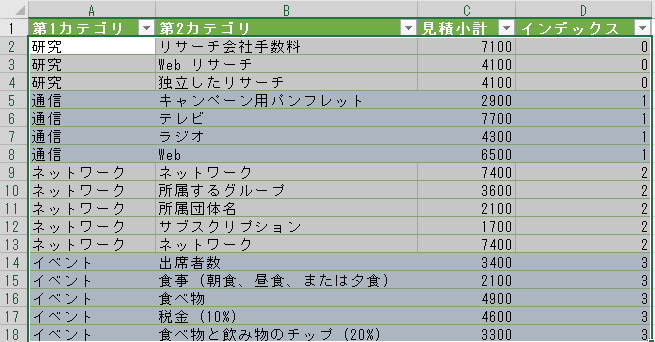
完成イメージは下図の通りだ。
グループ化
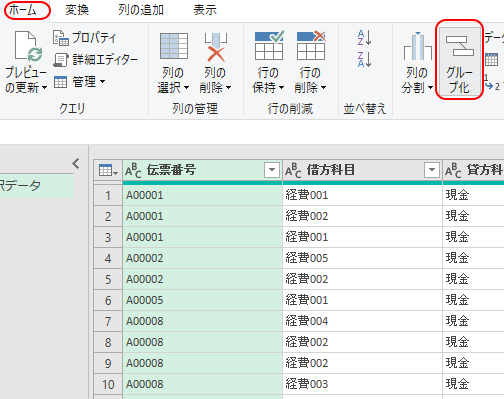
まず「伝票番号」列を選んだ状態で
リボン「ホーム」タブ
→グループ化
とする。
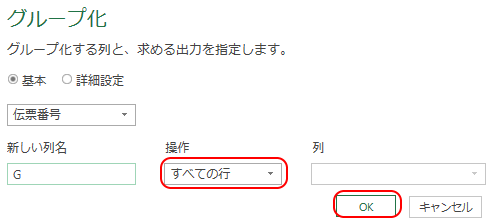
設定ダイアログが出るが、「新しい列名」にはひとまず「G」とでも入れる。
また「操作」欄では「すべての行」を選ぶ。
そして「OK」を押す。
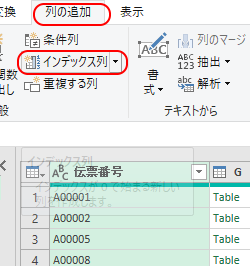
インデックスの追加
伝票番号ごとにグループ化されたので
リボン「列の追加」
→「インデックス列」
とする。
インデックスが追加されるが、数式バーまたは詳細エディターを確認すると、
Table.AddIndexColumn
という関数が確認できる。
これをコピペでもして、ちょっと覚えておこう。
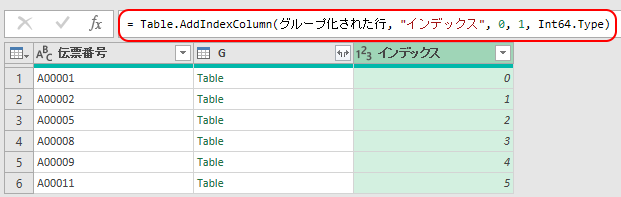

そして、先ほどのグループ化により追加された列「G」の、右端の四角ボタンを押して、データを展開する。
これで、「伝票番号」が変わるごとに1増えるインデックスが振られる。
インデックス設定(伝票番号が変わるごとに振り直し)
ステップの再加工
では今回の本題、伝票番号が変わるごとに0開始に戻るインデックスを設定していく。
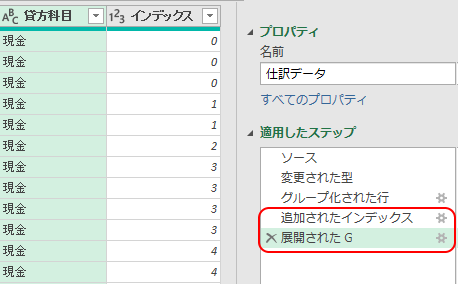
ここまでの処理で、クエリの「ステップ」が下図のように刻まれているはずだが、下の2ステップ
「追加されたインデックス」
「展開されたG」
を、左端の×印をクリックして削除しよう。
もちろん、最初からやり方を理解してるなら、そもそもこの最後の2ステップを作っておく必要もない。
カスタム列の追加→関数作成
伝票番号をキーにして「グループ化」されたばかりの状態に戻るが、ここからまたインデックス列を追加していく。
先ほどの例では「伝票番号」列をキーにしたインデックスを振ったが、今度は「伝票番号」列以外をキーにしてインデックスを振る感じ。
ただそのインデックスは、さっきのように単に「インデックス列」を押すとかでは作れず、ちょっと自分で関数を書いていかないと作れない。はず。
そのために
リボン「列の追加」タブ
→「カスタム列」
とする。
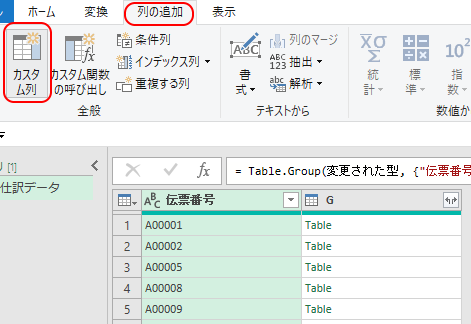
Table.AddIndexColumn関数を入れる
先ほどちょっと言及した
Table.AddIndexColumn
を入れていく。
カスタム列の式を入れる場所に「tab」とか最初の何文字かを入れれば、候補に「Table.AddIndexColumn」が出てくるはずなので、それを選択しよう。
普通に「Table.AddIndexColumn」文字列をコピペとかで入れても良いし。
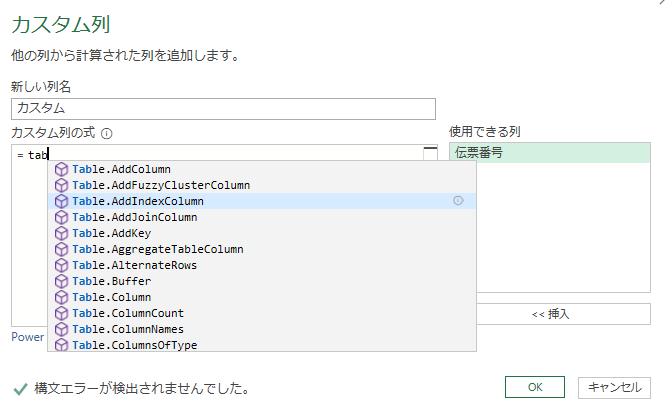
では、次のような条件のインデックス列を追加する。
- 「G」項目をグループ化キーとする。
- 0番開始
- 1ずつ増加
- 「行番号」という名前
ということで、関数の引数を次のように入れていく。項目「G」は、右端の「使用できる列」からダブルクリックで挿入すれば良い。
= Table.AddIndexColumn ( [G], “行番号” , 0 , 1)
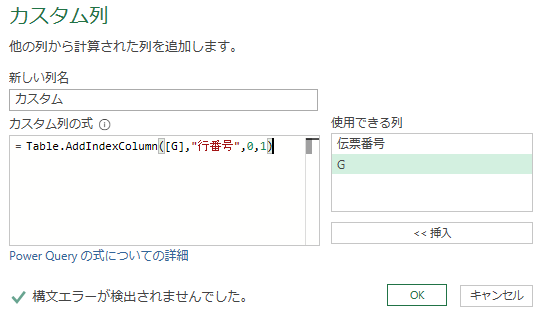
データの展開
下図のように「カスタム」列が追加され、「G」「カスタム」の2列が、データが折りたたまれた状態になる。
これらのうち「G」列は、もう不要なので削除して良い。
数式バーにTable.AddIndexColumn関数が確認できるけど、なんか他にもeachとか書かれてて、詳細エディターで自力で書くのはちょっと難しいと思う。
だからカスタム列機能を使って書いた。
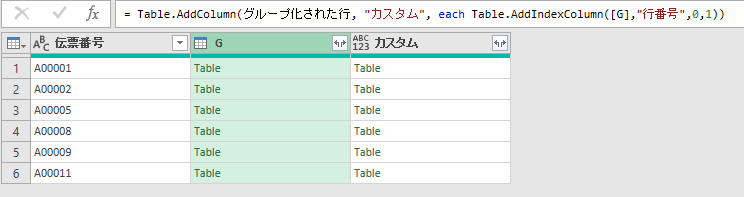
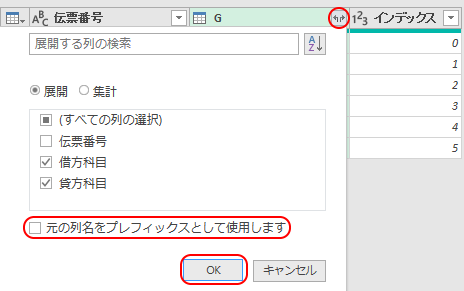
「カスタム」列の右端の四角ボタンを押して、データを展開する。
既にある項目「伝票番号」のチェックは外す。
また「元の列名をプレフィックスとして使用します」のチェックは外し「OK」を押そう。
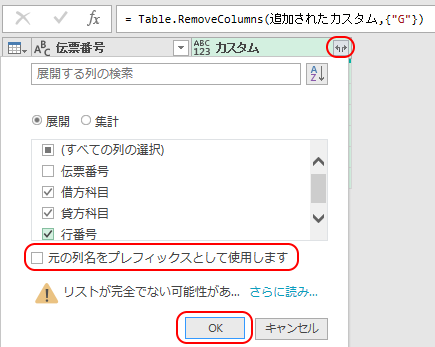
これで目的通り、「伝票番号」が変わるごとに0開始に戻る項目「行番号」が追加される。
いったん「伝票番号」以外をグループ化し、その内部でインデックス列を作り、またデータを展開した・・・という感じだ。
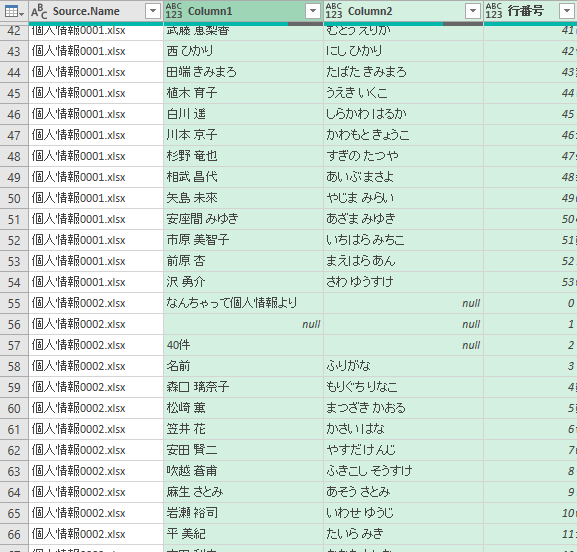
不要行の削除にも使える
以前の記事で、フォルダ内のExcelファイルを結合する例を扱ったが、この記事のとき使った各Excelファイルは、いずれも先頭4行が不要なものだった。
その先頭4行を燻り出すのにも、今回やったようなインデックス設定が使える。
下図では、ファイル名に当たる「Source.Name」列の値が変わるごとに「行番号」が0開始になるよう設定している。
その「行番号」が0~3の行をフィルタリングで削除するようにすれば、各ファイルの不要な先頭4行を削除できることになる。
スポンサーリンク